Раскрутка сайтов для Rambler

Продвижение ресурса в Rambler имеет свою специфику. Этот сервис заметно медленнее, чем Яндекс, проводит индексацию. Как учесть все нюансы? Читайте в нашей статье!
Вместо введения.
Rambler часто полагается на свой рейтинг TOP100, при этом индексация происходит довольно медленно.
Из личного опыта можно утверждать, что эта ПС любит уникальный контент больше, чем остальные. На выдачу здесь влияет наличие и положение в рейтинге Rambler TOP100.
Т.к. апдейты в Rambler происходят гораздо реже, чем в Google и Яndex, то гарантии на продвижение можно давать только при сроке не менее 6 месяцев.
Особенности работы поисковой машины Рамблер.
Rambler рассчитывает для каждого документа коэффициент популярности. Вот, что сказано разработчиками об этом коэффициенте: «Данный коэффициент, как и алгоритм PageRank, основан на учете гиперссылок между страницами сети, однако наша реализация дополнительно использует данные о реальной посещаемости, полученные от Top100. Дело в том, что «классические» ссылочные алгоритмы учитывают мнение только web-мастеров. Действительно, если им нравится тот или иной ресурс, они размещают на него гиперлинки. Счетчик Top100 как раз и предназначен для того, чтобы сделать коэффициент популярности более справедливым».
Судя по всему, в последнее время данные о посещаемости документов, полученные от Top100, оказывают все меньше и меньше влияют на популярность, так как алгоритм не в состоянии противостоять массовым накруткам, практикуемым владельцами некоторых порталов. Соответственно, все большее значение приобретает составляющая, вычисляемая на основе учета гиперссылок между страницами сети.
Отметим, что некоторые документы и даже целые сайты в поисковых машинах могут по той или иной причине исключаться из процесса расчета ранга, на который они ссылаются. Так, например, в Яндексе для этих целей существует так называемый «непот-фильтр». Он накладывается на ресурсы, находящиеся на бесплатных хостингах, но не описанные в Яндекс-каталоге, порталы со свободным размещением ссылок (например, гостевые книги, доски объявлений) и т.п.
Для повышения позиций необходимо работать над тем, чтобы как можно большее количество файлов сети ссылалось на него. Делать это можно по-разному: с помощью обмена ссылками с другими сайтами, регистраций в каталогах и др. Идеальный способ — сделать интернет-портал настолько уникальным и интересным, чтобы конкуренты сами считали необходимым поставить ссылку на него. Не следует также забывать, что при расчете класса документа учитываются как внешние, так и внутренние факторы. Поэтому грамотная перелинковка содержимого внутри сайта позволяет повысить ранг самых важных из них.
Механизм поисковой системы Рамблер
Полнота поиска в Рамблер
Полнота — это одна из основных характеристик ПС. Она представляет собой отношение количества найденных по запросу файлов к общему числу в Интернете, удовлетворяющих данному запросу. Например, если в сети имеется 100 страниц, содержащих словосочетание “Красная площадь”, а по соответствующему запросу было найдено всего 70 из них, то полнота поиска будет 0,7.
Это в большой мере зависит от работы системы сбора и обработки информации. В связи с постоянным ростом количества файлов в сети, эта система в первую очередь должна быть масштабируемой. В Рамблере масштабируемость достигается за счет параллельного исполнения задачи произвольным количеством машин.
Сбором сведений занимается робот-паук, который обходит странички с заданными URL и скачивает их в базу данных, а затем архивирует и перекладывает в хранилище суточными порциями. Робот размещается на нескольких платформах, и каждая из них выполняет свое задание. Хранилище у всех механизмов едино. При необходимости работу можно распределить, разбив список URL на 10 частей и раздав их 10 машинам. Параллельное действие программы позволяет легко выдерживать дополнительную нагрузку.
Сведения в сжатом виде собираются и разбиваются на куски по 50 Мб. Эти части постепенно распределяются между 70 программами-индексаторами. В результате на первом этапе формируется много маленьких хранилищ с данными со всего интернета.
После того, как вся информация обработана, начинается объединение результатов. Благодаря тому, что все базы имеют одинаковый формат, процедура объединения проходит просто и быстро, не требует никаких дополнительных модификаций. Основная площадка участвует в анализе как одна из составляющих нового индекса. Если объединяются 70 новых частей, то в анализе участвует 71 фрагмент (70 новых + основная база предыдущей редакции). Кроме того, единый формат позволяет обнаруживать ошибки на более раннем этапе.
Специальная программа (“сливатор”) составляет таблицы перенумерации файлов хранилища. Среди «пейджей» с одинаковыми адресами выбирается наиболее свежая версия; если при скачивании URL была ошибка 404 (запрашиваемая страница не существует), она временно удаляется из базы. Параллельно осуществляется склейка дублей.
Сборка общей базы представляет собой простой и быстрый процесс. Сопоставление страниц не требует никакой интеллектуальной обработки и происходит со скоростью чтения данных с диска. Если информации получается слишком много, то процедура “сливания” проходит в несколько этапов. Их может быть сколько угодно. Одни промежуточные базы сливаются в другие, а уже потом объединяются окончательно.
Точность поиска в Рамблере
Точность — еще одна основная характеристика ПМ. Она определяется как степень соответствия найденных данных запросу пользователя. Чем точнее поиск, тем быстрее человек находит нужное.
Повышение точности в Рамблере достигается за счет использования различных технологий на всех этапах обработки информации. Одним из наиболее интересных процессов является распознавание грамматических омонимов. Омонимы — это слова, имеющие одинаковое написание, но различный смысл. Различают лексические и грамматические омонимы. Лексические относятся к одной части речи, как, например, существительное “бор”: хвойный лес, стальное сверло и химический элемент. Грамматические — к разным частям речи, поэтому по написанию у них обычно совпадают только отдельные формы. Например: “печь” — существительное русская “печь” и глагол “печь” пирожки; “рядовой” — прилагательное “рядовой” сотрудник и существительное “рядовой” Иванов.
Омонимы не только увеличивают размер индексной базы (так как для каждого такого слова приходится хранить все его возможные значения), но и отрицательно сказываются на точности. Если покупатель ищет что-то конкретное, ему неинтересно получить в выдаче все документы с введенным словом. Для того, чтобы результаты поиска были точнее, модуль синтаксического анализа проводит разбор окружения слов-омонимов с целью установления их наиболее вероятных значений. Например, если рядом со словом “печь” стоит существительное (“пирожки”, “картошка”), то с высокой вероятностью “печь” в данном контексте является глаголом. На сегодняшний день анализатор способен распознавать значения только грамматических омонимов.
Синтаксический анализ позволяет с определенной вероятностью распознавать некоторые имена собственные. Если в тексте несколько слов подряд написано с большой буквы, они чаще всего представляют собой имя собственное (Петр Петрович, Московский Государственный Университет).
Еще один способ повышения точности поиска — это выделение устойчивых обозначений и поиск их как отдельных лексических единиц. На сегодняшний день в Рамблере реализована система распознавания таких конструкций, например C++, б/у, п/п-к. Если вбить в строку С++ и поднимать все тексты с латинской буквой С, а также со знаком +, то получится огромное количество ответов, не соответствующих запросу.
Огромную роль в этом процессе играет ранжирование. Человек очень редко просматривает больше трёх страниц с результатами поиска. Поэтому субъективно он оценивает точность по “верхним” результатам.
По умолчанию в описываемой ПС результаты ранжируются по релевантности и группируются. Параметры оценки текстов:
- Количество вхождений: чем больше раз фраза “Красная площадь” присутствует в тексте, тем выше вероятность, что в нем действительно говорится о Красной площади;
- Если словосочетание “Красная площадь” присутствует в заголовках или названии документа, то документ с большей вероятностью посвящен Красной площади;
- Формы слов запроса: преимущество отдается вхождениям,где слова имеют тот же падеж, число, склонение и т.д., что и в запросе пользователя. Помимо точного совпадения, выделяются две группы форм слов — близкие и далекие. Близкими считаются изменения по падежам, склонениям, спряжениям, числам и родам. Далекими — причастия, деепричастия и т.п. При ранжировании преимущество отдается близким формам.
- Относительная частота: если фраза встречается 10 раз из 100, то она скорее всего соответствует запросу.
- Расстояние между словами: если запрос состоит из нескольких частей речи, то в найденных документах оценивается, насколько близко друг от друга они расположены. Например, если слово “Красная” расположено в тексте на 5 позиции, а “площадь” — на 650, то текст не о Красной площади.
- Посещаемость документа: в некоторых случаях Рамблеру известна посещаемость. Преимущество отдается более посещаемым порталам.
- Ссылочный вес документа. Так, если на документ словами “Красная площадь” ссылается большое количество авторитетных источников, то ему отдается первенство.
Существуют различные способы, позволяющие уточнить поиск по отдельным запросам. В первую очередь к ним относится специальный язык. Используя его, можно ограничивать количество найденного. Например, взятые в кавычки КС обрабатываются буквально. Это повышает точность поиска, но уменьшает его полноту.
Использование логического оператора OR (ИЛИ) расширяет сферу поиска, в то время как оператор NOT (И-НЕ), наоборот, повышает точность за счет нахождения файлов с неполным соответствием. Можно также задавать расстояние между словами. Если в искомом словосочетании порядок слов обычно сохраняется, то имеет смысл ограничить расстояние, указав его в скобках через запятую. Это позволит отсеять результаты, в которых искомое разбросано по тексту.
Актуальность запросов в Рамблере
Актуальность — не менее значимая характеристика поиска. Она определяется временем, проходящим с момента публикации документов Интернете, до занесения их в индексную базу. Например, после теракта в Тушино огромное количество пользователей обратились к поисковой машине Рамблер с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток. Однако основные документы уже были заиндексированы и доступны для поиска, благодаря существованию “быстрой базы”, которая обновляется два раза в день, а при необходимости может обновляться быстрее.
На сегодняшний день индексная база Рамблера состоит из 8 частей. Каждая живет своей независимой жизнью. Весь Интернет условно разделен на 7 секторов и называется своим цветом: красный, оранжевый, желтый, зеленый, голубой, синий, фиолетовый. Сайт компании Рамблер относится к голубому сектору. Информация о web-ресурсах каждого сектора хранится в соответствующей части индексной базы. Восьмая часть — “быстрая база” — включает в себя страницы, на которых размещен счетчик Тор 100 и которые еще не успели попасть в основную индексную базу.
Все части собираются и обновляются по отдельности. Происходит переиндексация и обновление красного сектора, завтра — оранжевого и желтого, послезавтра — зеленого и т.д. Благодаря такому ступенчатому алгоритму в поисковой машине каждый день появляется свежая информация об одной седьмой части Интернета. Полный цикл обновления занимает около недели. При этом сбор информации происходит параллельно, а непосредственно на изготовление индекса документов одного сектора уходит всего несколько часов. Поэтому существует принципиальная возможность обновлять индексную базу быстрее.
Разделение Интернета на 7 секторов условно. При необходимости он может быть разбит на 10, 20 или 40 секторов, каждый из которых будет обрабатываться автономно. В такой системе заложена возможность значительного увеличения нагрузки. С ростом объема информации в сети Интернет растет и индексная база поисковой машины. Постепенно переиндексация и сборка базы начинает занимать все больше времени, а процесс обновления индекса становится более громоздким. Поступление новых данных затягивается, информация начинает терять свою актуальность. Возможность “передела” Интернета на большее число секторов позволяет удерживать размер каждой части базы в оптимальном диапазоне, контролировать время ее сборки и обновления.
“Быстрая база” отличается от остальных меньшим объемом и очень оперативным обновлением: время построения занимает около двух часов. Здесь содержится информация о страницах, на которых был установлен счетчик Тор 100. Участниками рейтинга Тор 100 являются новостные порталы, сайты крупных компаний, Интернет-магазины, форумы, — все наиболее популярные ресурсы в сети. Каждый раз при установке счетчика на новую страницу сайта, зарегистрированного в Тор 100, информация передается в поисковую систему. Страница ищется во всех цветах основной базы и, если она еще не известна поисковой системе, отправляется в очередь на обработку. Перед обработкой страницы дополнительно фильтруются, из них отбираются самые посещаемые. Таким образом, “сливки” с Интернета собираются два раза в день.
Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам. На сегодняшний день в рабочие часы к пионеру Рунета приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки. Интересы пользователя и ПС совпадают: посетитель хочет получить результаты как можно быстрее, а ПМ должна работать максимально оперативно. Схематично обработка поискового запроса изображена на рисунке 1.
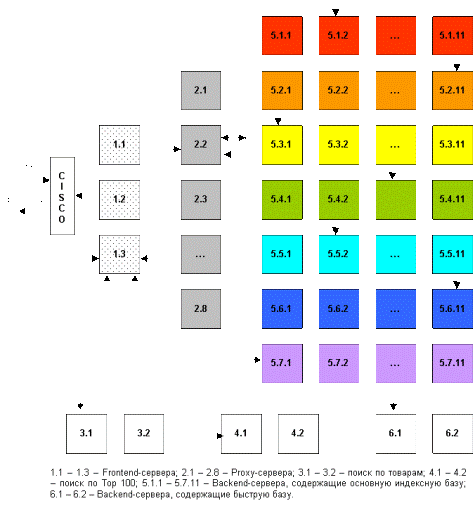
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из семи proxy-серверов, также выбирая наиболее свободный сервер (2.1 — 2.7, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.10, 5.3.1 и т.д.) Та же информация отправляется на машины с “быстрой базой” (6.1 — 6.2, на рис. 6.1).
На текущий момент в поиск включено около 70 backend’ов. Они сгруппированы по 10 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.10 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.10) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, результаты ранжирования сообщаются обратно proxy-серверу. Туда же поступают отсортированные материалы с “быстрой базы”. Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим — с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо данных с proxy-сервера, frontend получает сведения из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение итогов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco.
Каждый этап многократно продублирован и защищен системой балансировки нагрузки. Благодаря дублированию информации поисковая система Рамблер является устойчивой к сбоям на отдельных участках, авариям, отказам оборудования. Если одна их машин перестала функционировать, нагрузка перераспределяется на другие машины, и выпадения документов из поиска не происходит. Масштабируемость достигается простым добавлением в систему машин соответствующего уровня. До недавнего времени в Рамблере работало 40 backend’ов. В связи с тем, что осенью нагрузка на поисковые системы обычно возрастает, число backend’ов было увеличено до 70, что позволило значительно ускорить вычисление запросов.
Еще один способ повышения скорости поиска — “кэширование”, сохранение информации о запросах и результатах поиска в буфере. Многие люди дают одни и те же поисковые запросы. Вычислять их каждый раз заново было бы неразумной тратой времени. Поэтому если запрос уже обрабатывался в течение некоторого интервала времени, результаты поиска отдаются пользователю “из кэша”.
Лингвистический анализ текста документов и запроса позволяет ускорить обработку информации. Если нет специальных указаний, поисковая машина игнорирует стоп-слова, встречающиеся в запросе, чтобы не тратить время на обработку дополнительной информации, снижающей качество поиска.
Наглядность поиска
Наглядность является необходимым компонентом удобного поиска. На плохой витрине легко пропустить хороший продукт. Из-за нечеткости запросов, даже первые результаты выдачи не всегда содержат необходимую информацию. Это означает, что пользователю часто приходится проводить поиск внутри списка.
Группировка предназначена для того, чтобы на странице можно было вывести как можно больше Интернет-ресурсов, релевантных запросу пользователя. Это бважно, когда требуется получить данные из различных источников. Если более информативной для посетителя является дата обновления или релевантность отдельных составляющих, в ответной странице Рамблера существует возможность сортировки по этим параметрам.
В некоторых случаях полезным бывает знание названия сайта. Если пользователя интересует конкретный Интернет-ресурс, имя может дать ему гораздо больше информации, чем заголовок страницы или цитата.
Если запросу соответствует больше одного портала, то в качестве результата поиска предъявляется наиболее релевантная из них, а ниже располагается частичный список остальных. Это увеличивает количество полезной информации и часто позволяет уточнить поиск сразу.
Цитата определяет, насколько полезную информацию содержит найденный файл. Очень часто посетителю не требуется переходить по линку, чтобы обнаружить, что текст не соответствует его потребностям. Иногда ответ на вопрос содержится непосредственно в цитате документа. Это экономит время и повышает эффективность работы ПС.
Восстановить текст — единственный путь получить доступ к содержимому. Ресурс бывает недоступен по разным причинам. Документ может быть удален, перенесен, изменен, но его текстовое содержание некоторое время сохраняется в индексной базе. Кроме того, внутри самого документа часто отсутствует навигация, позволяющая быстро найти фрагмент, релевантный запросу. В восстановленном тексте все слова запроса подсвечиваются.
Алгоритм построения ассоциаций устроен так, что они почти всегда связаны между собой по смыслу. В некоторых случаях ассоциации позволяют повысить качество поиска за счет уточнения запроса (запрос “отдых в Польше” — ассоциации “отдых в Польше с детьми”, “семейный отдых”, “пансионаты в Польше”), исправления распространенных ошибок (запрос “gjujlf” — ассоциация “погода”), возможности сориентироваться в незнакомой тематике (запрос “антибиотик” — ассоциации “сумамед”, “цифран”, “бисептол” и т.д.)
К чему стремится Рамблер?
Главная задача разработчиков — улучшение качества работы, движение в сторону большей эффективности и удобства в использовании системы. С этой целью постоянно меняются поисковые алгоритмы, создаются дополнительные сервисы, дорабатывается дизайн.
Однако для того, чтобы выжить в Интернете, при разработке необходимо смотреть в будущее. Такой подход позволяет заниматься не только постоянной борьбой и приспособлением к растущим объёмам информации, но и реализовывать что-то новое.
К сожалению, на данный момент Рамблер как ПС больше не существует, т.к. использует поисковый движок от Яндекс. А ведь именно Rambler был «пионером» рунета, когда появлялись первые поисковые системы… Какой бесславный конец такого славного начала.